
Every now and again I look at Google Analytics for this site. It is visited fairly infrequently, although every now and again somebody arrives and spends a good long time clicking around. I want for this occasional visitor to have a good experience, and so I try to ensure a high-enough level of quality on the site. Do the links work? Is it usable by somebody with a screenreader? Did I remember to put alt text on all the images? Am I linking to secured (https) websites?
That’s a lot of things to keep track of. A year or so ago I made the decision to use some of the tools from my working career as a software engineer to automate this for myself. In particular, I wanted to do continuous integration on this website. continuous integration is the practice of automatically testing things every time you make a change, and making sure that you get quick automated feedback on your changes. This should help ensure that when I’m dashing off some page about what I’m excited to cook today, that there is a tool is ensuring I didn’t make any errors such as:
- Accessibility failures
- Broken links
- Straight-up typos and Broken HTML
- Badly styled code
- Adding links to insecurely configured sites
Now, I’m not an expert on a lot of these things (specifically accessibility), but would like to be able to guarantee a base level of quality and effort for everybody who does visit the site. As I’m not an expert myself, I ended up using a couple of tools that verify different things:
- markdownlint: Checks the markdown files that are compiled into this site for good style
- htmltest
- Checks the generated HTML for all manner of bad practices related to security, accessibility, etc.
- Checks that each link in a page is actually valid and working.
How Was CI Deployed?
I use CircleCI (although any number of other solutions would work out to be almost identical, e.g. GitHub actions, TravisCI).
The process of implementing CI for any of these providers is pretty much the same, although the details will differ. The introductory tutorials for each tool pretty much do everything we want, but at a high level the steps are:
- Write a script for CI to run. It should fail if there are any errors and succeed if the site is error-free.
- Add a YAML file to the repo that tells the CI tool what script to run
- Click some buttons in the CI tool to hook it up to your repo
Here is my CI script. It runs markdownlint, then builds the site and runs and installs htmltest. Nohing fancy at all.
#!/bin/bash
# This script test that the Jekyll site in the current directory passes
# Markdown linting and a run through htmltest.
#
# Expected state: mdl is available in the path, curl is installed
#
# Result: Non-zero return code indicates failure.
set -ex
# Lint all of the markdown files in the source tree
mdl .
jekyll build
# Install htmltest
curl https://htmltest.wjdp.uk | bash
HTMLTEST_OPTIONS="-c .htmltest.yml"
if [ -z "$1" ]; then
echo "Scanning entire site"
bin/htmltest ./_site $HTMLTEST_OPTIONS
else
echo "Scanning page $1"
bin/htmltest $1 $HTMLTEST_OPTIONS
fiIt’s worth noting that the CI process does find useful things. The thing that led to me writing this blog post was that I added a logo (the little Venn diagram) to the site. In the theme, the logo is configuration (simply add the name of the file to a config file), but when I merged that one-line change, CI started failing.
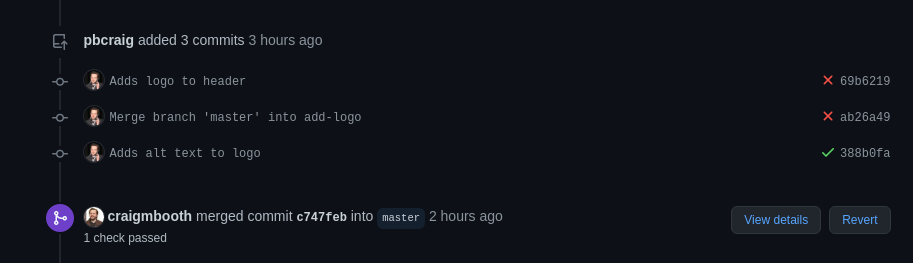
It turns out that the theme neglected to add alt text to the header image, making the site more difficult to navigate for people using a screenreader. The header image is a link to the front of my website, so added an alt text appropriately labeling it as such.
A Note On Implementing New Tools
I learned this particular technique from a software consultant I worked with who specialized in helping organizations to roll out new software systems. The advice he gave me was “Switch off almost everything in the new software and get one thing working. Once that works, switch on a second thing, then a third”.
The reasoning behind that advice was that the quickest way to learn to ignore something (or never internalize that is exists) is for it to be noisy on day one, before it has demonstrated its value.
I markdown linted this site following exactly this philosophy. The first time I ran mdl, there were probably 300 failures, it was an absolutely overwhelming number that I had no idea where to start with.
My approach ended up being the following:
- Disable all the failing rules (initally this was over half of them).
- At this point I have working CI! It’s only checking half of the rules, but whatever, it’s making sure I don’t add new mistakes.
- Over the next few (dozen) pull requests, enable rules one by one. Each time this happens, make the decision about whether to fix the markdown, or leave the rule in the list of disabled rules.
After going through this process, I ended with a completely tractable list of ignored rules, which I understand well, and a site that obeys markdown best practices.
# MD002 First header should be a top level header
# Jekyll's title is the h1 on the page. The first heading in a post should be the h2
exclude_rule 'MD002'
# MD013 Line length
# There are just a lot of these to fix
exclude_rule 'MD013'
# MD026 Trailing punctuation in header
# I write the occasional header that ends in ?
exclude_rule 'MD026'
# MD033 Inline HTML
# Just use inline html sometimes
exclude_rule 'MD033'
# MD041 First line in file should be a top level header
# Excluded because Jekyll files have a preamble
exclude_rule 'MD041'I have found this approach to be one that is successful very much of the time: Get one thing working, and gradually switch on more.